AICC上使用Mindformers教程¶
AICC,人工智能计算中心,提供ModelArts服务和Ascend 910算力。
MindFormers套件当前具备AICC适配的特性,用户在ModelArts平台启动集群训练时,无需额外增加上云训练适配代码,套件将自动进行:
从OBS拉取训练所需数据至训练镜像
统一训练输出路径
训练后将训练输出整体回传指定文件夹
训练过程中,通过回调函数将训练输出回传至指定文件夹
下面将提供在AICC上完成GPT2模型的训练样例,用户可以按照此样例学习MindFormers套件在ModelArts训练作业上的使用方式
使用前需对AICC的AI开发平台ModelArts,对象存储服务 OBS和容器镜像服务 SWR有初步的了解
准备工作¶
模型准备¶
本案例使用MindFormers套件内的GPT2模型作为教程案例,请参照GPT2进行模型代码和训练数据集的准备
模型代码
git clone https://gitee.com/mindspore/mindformers.git
数据集预处理 以Wikitext2数据集为例
数据集下载:WikiText2数据集
词表下载:vocab.json,merges.txt
参考ModelZoo,将数据处理成Mindrecord格式。注:训练数据处理时,长度应等于模型接收长度加一
云上对象存储准备¶
准备好代码与数据集后,需将其上传至AICC的对象存储服务上
进入
存储标题下的对象存储服务,将训练代码和数据等输入内容上传,并准备好用于回传训练输出的路径;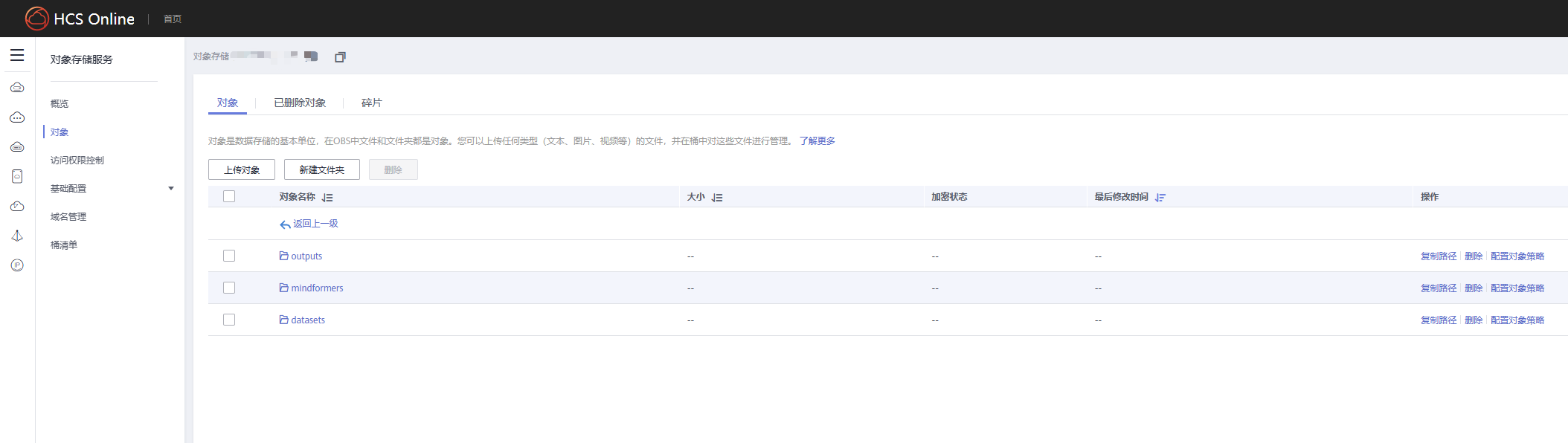
进入
对象存储服务的任一文件夹,点击界面上方的复制按钮,即可获得当前文件夹的OBS路径映射 如:obs://huawei/xxx/mindformers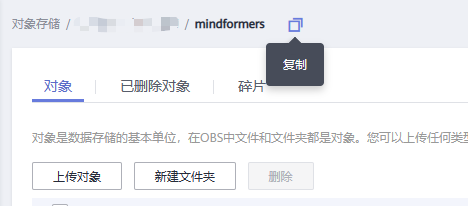
镜像准备¶
ModelArts上的所提供的预置训练镜像,通常MindSpore的版本较为老旧,不满足MindFormers套件的运行需求,所以通常需要自定义镜像,安装合适版本的MindSpore包以运行套件
我们在镜像仓库网 (hqcases.com)上发布了一些经过验证的标准镜像版本,可以通过几行简单的docker命令的形式,直接使用验证过的标准镜像拉起MindFormers套件的训练任务,而无需进行较为繁琐的自定义镜像并上传的步骤
在镜像仓库网上找到当前版本的MindFormers镜像,打开显示如下(截图部分仅供参考,具体镜像版本以链接为主)

可以复制其docker pull命令拉取该镜像,在镜像仓库网上的镜像权限均为公开,无需登录可以直接拉取
注:当前版本镜像为每日开发版,稳定版将在后续推送至镜像仓库网
镜像列表
1. swr.cn-central-221.ovaijisuan.com/mindformers/mindformers_dev_mindspore_1_10_1:mindformers_0.6.0dev_20230615_py39
在一台准备好docker引擎的计算机上,root用户执行docker pull命令拉取该镜像
docker pull swr.cn-central-221.ovaijisuan.com/mindformers/mindformers_dev_mindspore_1_10_1:mindformers_0.6.0dev_20230615_py39
进入
容器镜像服务的控制台界面,找到客户端上传镜像按钮,将会提示如何上传上一步拉取的镜像
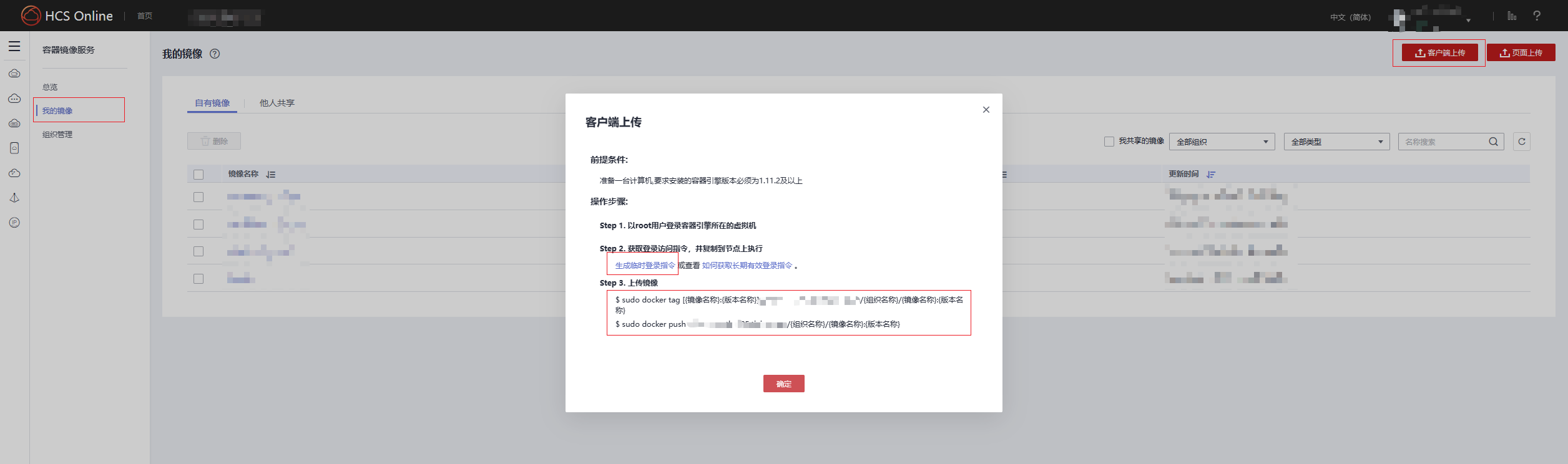
按照操作执行完后将会在该镜像列表中看到上传的镜像,并能够在ModelArts中选取
拉起训练流程¶
训练作业配置¶
进入
ModelArts控制台的训练作业功能区,点击页面右上角的创建作业按钮,开始创建训练作业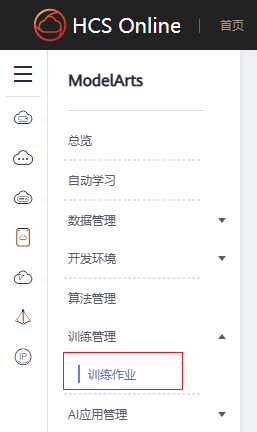
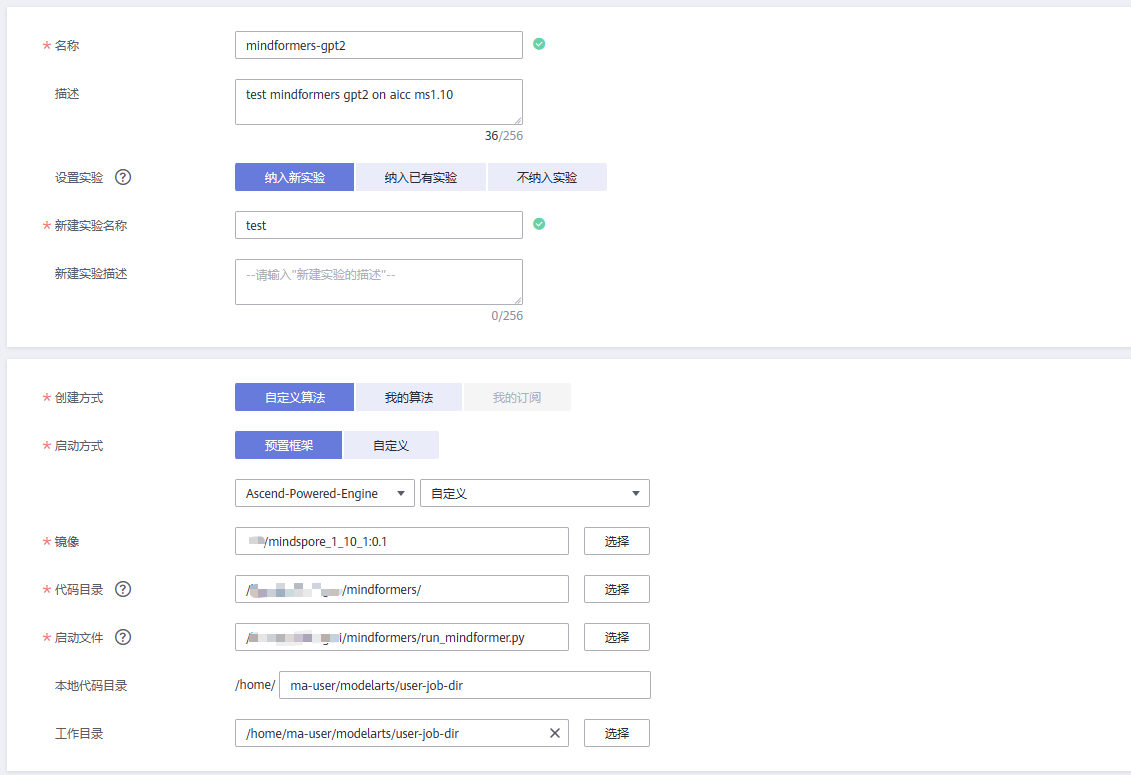
名称/描述/新建实验名称:按实际填写即可
创建方式/启动方式: 我们需要使用之前准备的镜像环境,但拉取方式仍可复用预置命令
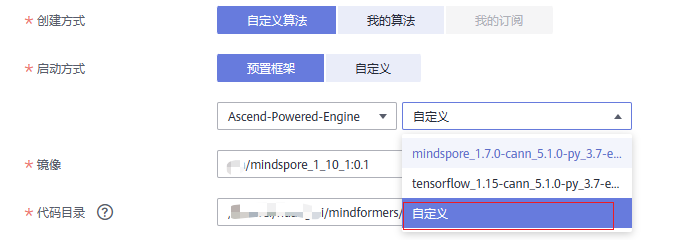 这里选择自定义,即可在镜像一栏选择之前准备并上传好的镜像
这里选择自定义,即可在镜像一栏选择之前准备并上传好的镜像代码目录选择上传的代码路径
启动文件选择run_mindformers.py脚本
注意,在AICC上拉起训练任务时,即使需要多卡启动,也只需指定python脚本作为启动文件,作业启动引擎会自动完成ranktable与环境变量等内容的配置,并多进程拉起python脚本,不需要额外的分布式启动shell脚本
本地代码目录与工作目录保持默认即可
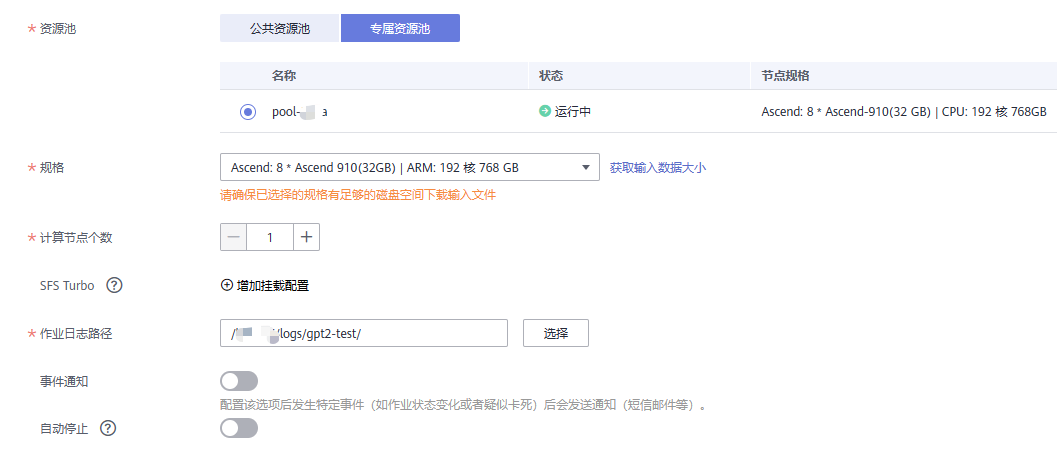
按需求选择资源池,规格和计算节点数,配置作业日志回传路径 卡数=单节点规格数 * 节点数
下面将较为详细地解释不同情况下拉起训练时所需的每个入参及其含义
从头训练¶
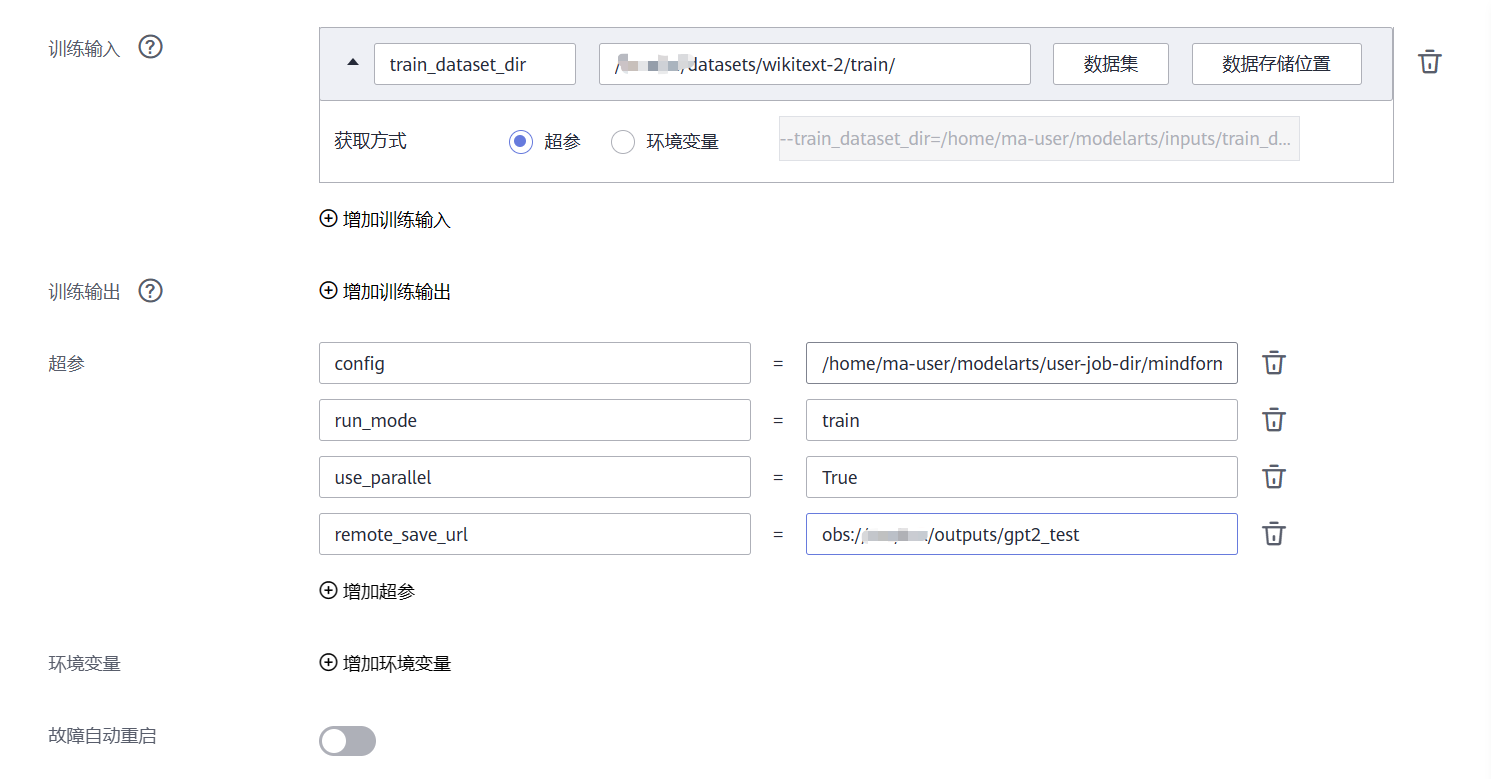
训练输入:
train_dataset_dir:选择数据集在云上的数据存储文件夹位置,作为训练数据集的路径;该参数名应当能够被启动脚本识别
选择后,ModelArts将会在拉起训练作业时,将云上的数据集拉取至指定的目录下,然后将该入参的值从云上路径修改为镜像上被拉取的路径
训练输出:
启用时,需要将文件输出在超参传入的路径下,训练结束后会进行回传;
由于输出通常较大,默认的路径下磁盘空间不足,我们会将输出统一放在/cahce目录下,因此MindFormers不启用该项参数
必需超参:
config:填入对应config文件在训练服务器上的绝对路径,在本案例下为/home/ma-user/modelarts/user-job-dir/mindformers/configs/gpt2/run_gpt2.yaml,亦或是通过环境变量/${MA_MOUNT_PATH}/mindformers/configs/gpt2/run_gpt2.yamlrun_mode:train,训练模式,将不加载权重进行训练use_parallel:True,在所选规格参数大于1卡时需要设置为True,单卡运行为Falseremote_save_url:obs://xxx/xxx/outputs/gpt2_test,填入对象存储服务中实际准备的OBS路径,训练输出将会回传至该路径下,需要显式写出obs://
其余可选超参可参照
run_mindformers.py脚本入参进行选择
全参微调¶
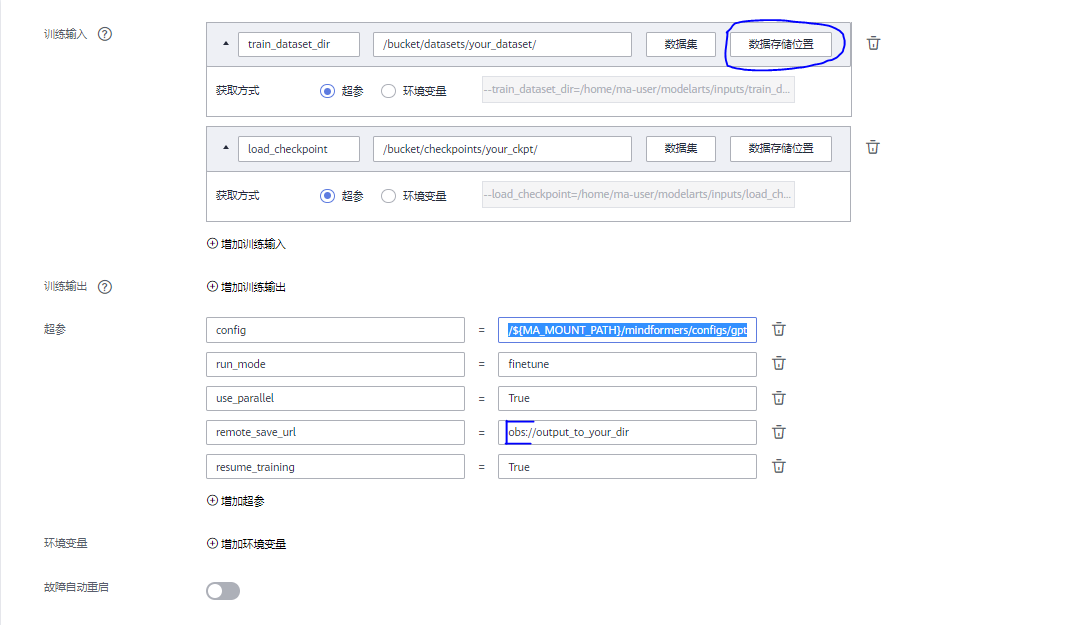
以下列出需额外增加部分参数:
训练输入:
load_checkpoint: 在finetune模式下必须指定,需要finetune的权重的obs路径(通过数据存储位置直接选择obs中位置)
选择后,ModelArts将会在拉起训练作业时,将云上的数据集拉取至指定的目录下,然后将该入参的值从云上路径修改为镜像上被拉取的路径
必需超参:
run_mode:finetune,微调模式,必须加载权重(在训练输入中设置)resume_training: 断点续训所需参数,正常微调需设为false,或者不设置
其余输入/输出/超参与全参微调一致
低参微调¶
使用lora等算法进行低参微调时,与全参微调没有区别,需要把config指定为使用lora微调的config
训练输入:
load_checkpoint: 低参微调时,该路径与全参微调一致,需指定finetune使用的原始权重
选择后,ModelArts将会在拉起训练作业时,将云上的数据集拉取至指定的目录下,然后将该入参的值从云上路径修改为镜像上被拉取的路径
必需超参:
config:填入对应config文件在镜像上的绝对路径,在本案例下为/home/ma-user/modelarts/user-job-dir/mindformers/configs/gpt2/run_gpt2_lora.yaml
其余输入/输出/超参与全参微调一致
断点续训¶
训练或微调,遇到训练中断的情况,如果保存了ckpt,则可以保存处继续训练。
如果run_mode为train的情况下训练中断,恢复训练步骤如下:
重建训练
其余设置不改变,增加超参
resume_training设置为true增加训练输入
load_checkpoint,通过数据存储位置直接选择obs中需要恢复的ckpt拉起训练即可加载权重,优化器状态,loss scale,step等继续训练
如果run_mode为finetune的情况下训练中断,恢复训练步骤如下:
重建训练
其余设置不改变,增加超参
resume_training设置为true需要变更
load_checkpoint,通过数据存储位置选择obs中需要恢复的ckpt拉起训练即可加载权重,优化器状态,loss scale,step等继续训练
finetune恢复训练示例如下
权重保存相关修改¶
保存ckpt相关的配置需要修改config配置文件中CheckpointMointor
save_checkpoint_steps:可修改保存ckpt频率;
prefix:可修改保存ckpt名字前缀
# callbacks
callbacks:
- type: MFLossMonitor
- type: SummaryMonitor
keep_default_action: True
- type: CheckpointMointor
prefix: "gpt2"
save_checkpoint_steps: 500
integrated_save: False
async_save: False
- type: ObsMonitor
eval_callbacks:
- type: ObsMonitor
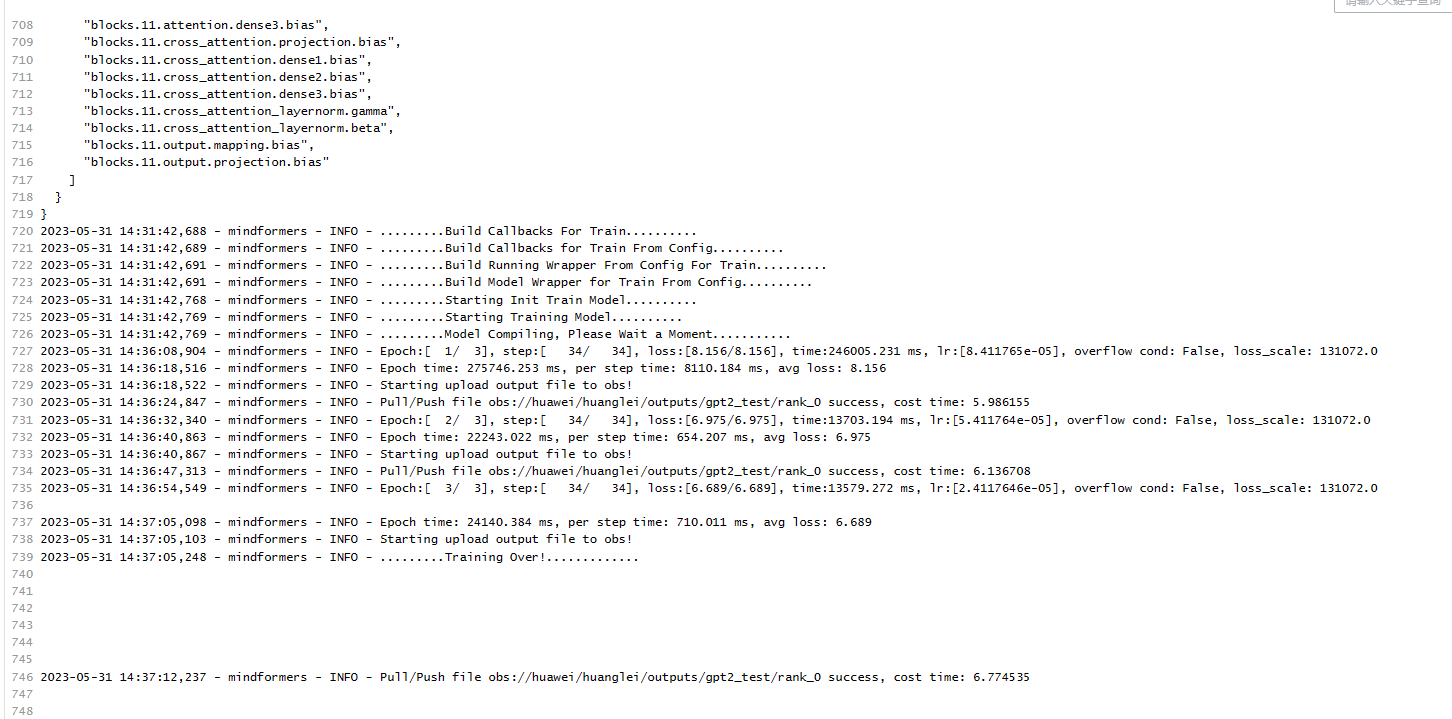
常见问题¶
启动作业后报module not found: 标准镜像可能缺少几个pip安装包,将相应的包名加入代码主目录下的requirements.txt文件下,拉起时会自动读取并安装相应的包
回传过于频繁导致影响训练 可以通过所训练模型的配置文件
callback中ObsMonitor新增参数upload_sequence:表示多少step回传一次output目录下的内容到obs中。
# callbacks
callbacks:
- type: MFLossMonitor
- type: SummaryMonitor
keep_default_action: True
- type: CheckpointMointor
prefix: "mindformers"
save_checkpoint_steps: 100
integrated_save: True
async_save: False
- type: ObsMonitor
upload_sequence: 10000
eval_callbacks:
- type: ObsMonitor
权重离线切分转换¶
注意:mindformers/tools/transform_ckpt.py转换接口仅在MindSpore2.0环境下使用,可以在NoteBook中安装MindSpore2.0 CPU版本,进行离线转换;
step1
在
config或者训练作业中配置超参only_save_strategy=True,拉起训练作业,仅生成分布式策略文件。生成的分布式策略文件保存在
remote_save_url/strategy目录下。(remote_save_url表示obs存储路径)训练作业界面中增加
only_save_strategy超参
step2
启动NoteBook任务,运行如下脚本完成权重切分转换(注意在MindSpore 2.0版本下)
python mindformers/tools/transform_ckpt.py --src_ckpt_strategy SRC_CKPT_STRATEGY --dst_ckpt_strategy DST_CKPT_STRATEGY --src_ckpt_dir SRC_CKPT_DIR --dst_ckpt_dir DST_CKPT_DIR
参数说明
src_ckpt_strategy:待转权重的分布式策略文件路径。
若为None,表示待转权重为完整权重;
若为切分策略文件,表示原始的权重对应的策略文件;
若为文件夹,表示需要合并文件夹内策略文件(仅在流水并行生成的策略文件时需要),合并后的策略文件保存在SRC_CKPT_STRATEGY/merged_ckpt_strategy.ckpt路径下;
dst_ckpt_strategy:目标权重的分布式策略文件路径。即step1中生成的分布式策略文件路径。
若为None,表示将待转权重合并为完整权重;
若为切分策略文件,表示目标卡数对应的策略文件
若为文件夹,表示需要合并文件夹内策略文件(仅在流水并行生成的策略文件时需要),合并后的策略文件保存在DST_CKPT_STRATEGY/merged_ckpt_strategy.ckpt路径下;
src_ckpt_dir: 待转权重路径,须按照SRC_CKPT_DIR/rank_{i}/checkpoint_{i}.ckpt存放,比如单一权重存放格式为SRC_CKPT_DIR/rank_0/checkpoint_0.ckpt。
dst_ckpt_dir:目标权重保存路径,为自定义空文件夹路径,转换后模型以DST_CKPT_DIR/rank_{i}/xxx.ckpt存放。
step3
将切分转换好的权重传到OBS
step4
训练作业界面中增加load_checkpoint超参,输入转换好的checkpoint的文件夹obs路径。