Parallel¶
《并行专题介绍》
前言¶
分布式并行场景¶
超大规模图像分类与识别
这类网络往往有一个超大FC层以及loss层。在人脸识别和超大规模图像分类领域,分类数可能高达千万,FC层参数量能到达到10B级别。这类网络即使在数万分类这种场景,模型并行相对数据并行来说性能也能更优,因为数据并行通信的是参数梯度,通信数据量等于参数量,而模型并行通信的是feature map,这类网络feature map的数据量远小于参数的数据量,进而在通信上能够性能更优。
高分辨率3D图像处理
例如医疗领域的3维CT图像处理,典型网络是Unet-3D。这类场景,输入图像往往有亿级像素,模型的Feature Map非常大,叠加上比较深的网络结构,模型也往往是数百GB;
NLP领域
NLP领域,目前基于Transformer结构的网络是SOTA方法,最典型网络的大网络有GPT2/3、Google翻译、FaceBook翻译等模型。基于Transformer结构的网络,从bert的340M参数,transformer-xl 800M参数,gpt-2 1542M参数,NVIDIA megatron有8B参数、GPT-3的175B参数。往往更大的网络,就需要用更大的数据来喂,训练这类网络,就需要使用数据并行叠加模型并行的方式,同时处理大规模数据集及大规模参数。
推荐网络 Wide&Deep/DeepFM/DCN等
在推荐领域,特征数量是百亿甚至千亿的规模,会有超大Embedding层,内存开销远超单卡内存,就必须使用模型并行把Embedding参数切分到集群。
总的来说,不同场景的模型,结构各有不同,如下图所示,不同结构的模型,需要不同的并行策略,才能实现性能的最优。图中方块的大小表示layer的内存开销。

Transformer一般会采用数据并行叠加模型并行的策略;推荐一般会采用模型并行转数据并行的策略;ReID一般会采用数据并行转模型并行的策略;
MindSpore分布式并行模式简介¶
当前MindSpore提供分布式并行训练的功能,它支持了多种模式包括:
并行模式 |
配置 |
动态图 |
静态图 |
支持设备 |
|---|---|---|---|---|
数据并行 |
DATA_PARALLEL |
支持 |
支持 |
GPU、Ascend 910 |
半自动并行 |
SEMI_AUTO_PARALLEL |
不支持 |
支持 |
GPU、Ascend 910 |
全自动并行 |
AUTO_PARALLEL |
不支持 |
支持 |
GPU、Ascend 910 |
混合并行 |
HYBRID_PARALLEL |
不支持 |
支持 |
GPU、Ascend 910 |
DATA_PARALLEL:数据并行模式。用户的网络参数规模在单卡上可以计算的情况下使用。这种模式会在每卡上复制相同的网络参数,训练时输入不同的训练数据,适合大部分用户使用。AUTO_PARALLEL:自动并行模式。融合了数据并行、算子级模型并行的分布式并行模式,可以自动建立代价模型,找到训练时间较短的并行策略,为用户选择合适的并行模式。当前MindSpore支持算子级并行策略的自动搜索,提供了如下的三种不同的策略搜索算法:dynamic_programming:动态规划策略搜索算法。能够搜索出代价模型刻画的最优策略,但在搜索巨大网络模型的并行策略时耗时较长。其代价模型是围绕Ascend 910芯片基于内存的计算开销和通信开销对训练时间建模。recursive_programming:双递归策略搜索算法。对于巨大网络以及大规模多卡切分能够保证瞬间生成最优策略。其基于符号运算的代价模型可以自由适配不同的加速器集群。sharding_propagation:切分策略传播算法。由配置并行策略的算子向未配置的算子传播并行策略。在传播时,算法会尽量选取引发张量重排布通信最少的策略。关于算子的并行策略配置和张量重排布,可参考这篇设计文档。
该模式适用于用户的神经网络在单卡上无法计算,但是不知道如何配置算子策略。用户启动这种模式,MindSpore会自动针对每个算子进行配置策略,适合想要并行训练但是不知道如何配置策略的用户。
SEMI_AUTO_PARALLEL:半自动并行模式。相较于自动并行,该模式需要用户对算子手动配置切分策略实现并行。HYBRID_PARALLEL:混合并行模式。在MindSpore中特指用户通过手动切分模型实现混合并行的场景。该模式完全由用户自己设计并行训练的逻辑和实现,用户可以自己在网络中定义AllGather等通信算子,适合熟悉并行训练的用户。
MindSpore 分布式并行设计¶
设计抽象¶
MindSpore目前是基于集合通信的模式来实现并行,如下图所示,分布式并行问题可以抽象成这样一个问题:
将计算图(Graph)和Tensor切分到集群并行执行,并能保持高性能。

从Tensor切分角度看数据并行、模型并行和混合并行。
如下图所示,数据并行就是在输入数据Tensor的batch维度切分,模型并行就是对模型参数Tensor的切分,而混合并行就是对输入数据Tensor和模型参数Tensor同时切分。

设计目标¶
MindSpore自动并行的目标是构建一种易用高效的的分布式并行训练模式,融合了数据并行、模型并行和混合并行,让算法人员不再需要关注算法模型到底需要用哪种模式训练。主要目标是:
简化分布式并行编程,串行代码实现分布式训练,对用户屏蔽并行细节,并且保持高性能;
计算逻辑上保持和单卡串行流程一致;
实现上统一数据并行和模型并行,一套框架支持多种并行模式;
结合集群拓扑优化性能;
实现上,就像前面介绍一下,MindSpore的自动并行分成两部分,半自动并行和全自动并行。
半自动并行:主要是在图编译阶段实现了一套算子切分及图切分的框架,把模型切片和设备进行调度绑定。在API这层,把并行逻辑和算法逻辑解耦,变成了一些配置。
自动并行:其在半自动并行基础上,构建了一套Cost Model,能够了基于数据量、模型参数量、网络集群拓扑带宽等信息的代价模型,通过一套策略搜索算法,计算是性能最优的切分策略,这样用户就不需要感知切分策略。
数据并行和自动并行¶
数据并行¶
数据并行是业界非常常用的并行方式,本章节开始介绍MindSpore中ParallelMode.DATA_PARALLEL数据并行的实现原理和使用方式。
数据并行原理¶
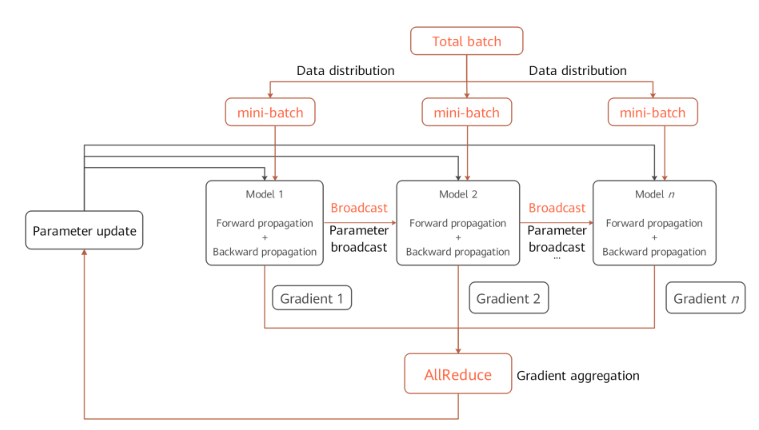
环境依赖
每次开始进行并行训练前,通过调用
mindspore.communication.init接口初始化通信资源,并自动创建全局通信组WORLD_COMM_GROUP。数据分发(Data distribution)
数据并行的核心在于将数据集在样本维度拆分并下发到不同的卡上。在
mindspore.dataset模块提供的所有数据集加载接口中都有num_shards和shard_id两个参数,它们用于将数据集拆分为多份并循环采样的方式,采集batch大小的数据到各自的卡上,当出现数据量不足的情况时将会从头开始采样。网络构图
数据并行网络的书写方式与单机网络没有差别,这是因为在正反向传播(Forward propagation & Backward Propagation)过程中各卡的模型间是独立执行的,只是保持了相同的网络结构。唯一需要特别注意的是为了保证各卡间训练同步,相应的网络参数初始化值应当是一致的,在
DATA_PRALLEL和HYBRID_PARALLEL模式下建议通过使能parameter_broadcast达到权重广播的目的;在AUTO_PRALLEL和SEMI_AUTO_PARALLEL模式下,框架内部会自动分析参数的并行度,并设置相应的随机数种子,保证在数据并行维度的设备上参数初始化值一致。梯度聚合(Gradient aggregation)
数据并行理论上应该实现和单机一致的训练效果,为了保证计算逻辑的一致性,在梯度计算完成后插入
AllReduce算子实现各卡间的梯度聚合操作。MindSpore设置了mean开关,用户可以选择是否要对求和后的梯度值进行求平均操作,也可以将其视为超参项,打开开关等价于学习率倍数缩小。参数更新(Parameter update)
因为引入了梯度聚合操作,所以各卡的模型会以相同的梯度值一起进入参数更新步骤。因此MindSpore实现的是一种同步数据并行训练方式。理论上最终每卡训练出来的模型是相同的,如果网络中含有在样本维度的归约类型操作,网络的输出可能会有所差别,这是由数据并行的切分性质决定的。
数据并行代码¶
集合通信
management.py:这个文件中涵盖了集合通信过程中常用的
helper函数接口,例如获取集群数量和卡的序号等。当在Ascend芯片上执行时,框架会加载环境上的libhccl.so库文件,通过它来完成从Python层到底层的通信接口调用。comm_ops.py:MindSpore将支持的集合通信操作都封装为算子的形式放在这个文件下,包括
AllReduce、AllGather、ReduceScatter和Broadcast等。PrimitiveWithInfer中除了定义算子所需属性外,还包括构图过程中输入到输出的shape和dtype推导。
梯度聚合
grad_reducer.py:这个文件实现了梯度聚合的过程。对入参
grads用HyperMap展开后插入AllReduce算子,这里采用的是全局通信组,用户也可以根据自己网络的需求仿照这个模块进行自定义开发。MindSpore中单机和分布式执行共用一套网络封装接口,在Cell内部通过ParallelMode来区分是否要对梯度做聚合操作,网络封装接口建议参考TrainOneStepCell代码实现。
数据并行案例¶
在数据并行中,用户定义网络的方式和单机脚本一样,但是在网络定义之前调用init()去初始化设备通信状态。
import numpy as np
import mindspore as ms
from mindspore.communication import init
from mindspore import ops, nn
class DataParallelNet(nn.Cell):
def __init__(self):
super(DataParallelNet, self).__init__()
# 初始化权重
weight_init = np.random.rand(512, 128).astype(np.float32)
self.weight = ms.Parameter(ms.Tensor(weight_init))
self.fc = ops.MatMul()
self.reduce = ops.ReduceSum()
def construct(self, x):
x = self.fc(x, self.weight)
x = self.reduce(x, -1)
return x
init()
# 设置并行模式为数据并行,其他方式一致
ms.set_auto_parallel_context(parallel_mode=ms.ParallelMode.DATA_PARALLEL)
net = DataParallelNet()
model = ms.Model(net)
model.train(*args, **kwargs)
自动并行¶
自动并行作为MindSpore的关键特性,用于实现自动的数据并行加模型并行的混合并行训练方式,旨在帮助用户以单机的脚本表达并行算法逻辑,降低分布式训练难度,提高算法研发效率,同时又能保持训练的高性能。这个小节介绍了在MindSpore中ParallelMode.AUTO_PARALLEL自动并行模式及ParallelMode.SEMI_AUTO_PARALLEL半自动并行模式是如何工作的。
自动并行原理¶
下面给出MindSpore自动并行原理设计图:
注意:图示的Shard Strategy Search中缺少 Sharding Propagation方法,这是目前自动并行推荐的策略自动配置方法
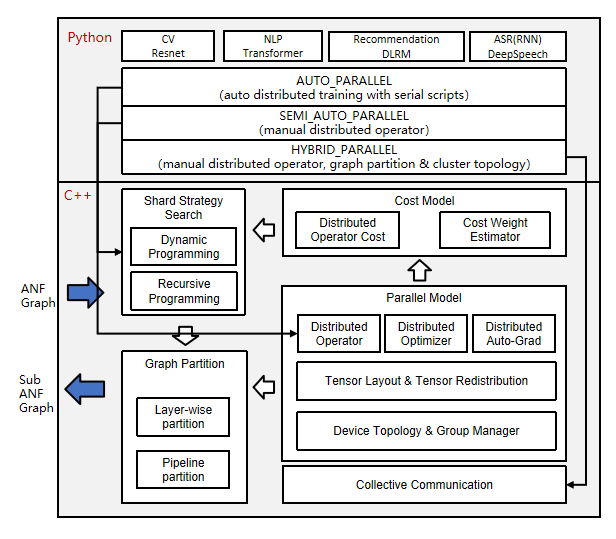
可以看到,图中给出了自动并行实现的关键流程,其中需经过一些关键操作完成整个自动并行的实现,这里先介绍一下基本的概念:
关键概念
关键概念
说明
ANF(Accelerate Network Forward) Graph
正向计算图
Sub ANF Graph
正向计算子图
Graph Partition
图切分
Layer-wise partition
按layer切分
Pipeline partition
按stage/block切分
Distributed Operator
分布式算子
Distributed Optimizer
分布式优化器
Distributed Auto-Grad
分布式自动微分
Tensor Layout
张量排布(张量被切分之后在集群上的分布情况)
Tensor Redistribution
张量重排 (两种Tensor Layout之间的转换)
当上一个算子的输出切分策略和下一个算子的输入切分策略不匹配时,会触发张量重排,会自动插入一些通信算子以保证计算逻辑的正确性Device Topology
设备拓扑
Group Manager
群组管理
Cost Model
代价模型
Distributed Operator Cost
计算分布式算子代价(确定分布式算子切分策略)
Cost Weight Estimator
估计分布式算子的重要性(估计分布式算子不同切分策略的权重占比)
算子级切分¶
本小接将会介绍如何基于上述并行原理中的**分布式算子和张量排布模型(Distributed Operator && Tensor Layout)**来实现MindSpore中的算子切分。
计算图中的分布式算子计算流程
首先对每个算子的输入tensor按策略进行切分,生成算子输入的tensor layout,然后根据算子的数学定义,推导出输出tensor layout;
然后再检查前一个算子输出tensor layout和下一个算子的输入tensor layout,如果两种不同,则会插入一个tensor redistribution。

Tensor Layout表示tensor切分后,tensor切片在集群分布情况。
Tensor Redistribution表示两种Tensor Layout之间的转换。
Note:这种建模设计充分地表达了张量和设备间的映射关系,用户无需感知模型各切片放到哪个设备上运行,框架会自动调度分配。
如何得到每个算子的张量排布模型??? 为了得到张量的排布模型,每个算子都具有切分策略(Shard Strategy),它表示算子的各个输入在相应维度的切分情况。 MindSpore中目前支持用户手动对算子进行shard配置或使用全自动并行模式进行自动获取两种形式。
切分策略配置原则???
通常情况下只要满足以2为基、均匀分配的原则,张量的任意维度均可切分;
MindSpore为内置算子均实现了shard属性,用户可以通过operator.shard()来为单算子的输入或者输出配置相应的切分策略;
shard属性的入参:
.shard(in_strategy, out_strategy),其中in_strategy,out_strategy分布表示算子的输入、输出的切分策略,且均需以元组形式传入,比如当算子本身只需一个Tensor输入时,in_strategy=((1, 1, 1),),当算子本身需要两个Tensor输入时,in_strategy=((1, 1, 1), (1, 1, 1)),以此类推即可。不切分的维度shard策略写1,需要切分的维度能够被切分策略整除(建议切分策略以2为基数,被切分之后的tensor shape仍是2的倍数,可以获得较好的切分性能);
如果一个算子同时对输入的数据和模型权重同时切分,假设数据(batch维度)部分切dp份,模型权重部分切mp份,需要满足
dp * mp <= total_device_num
算子级切分用例
以下图为例,这是一个三维矩阵乘(BatchMatMul)操作,它的切分策略由两个元组构成,分别表示input和weight的切分形式。
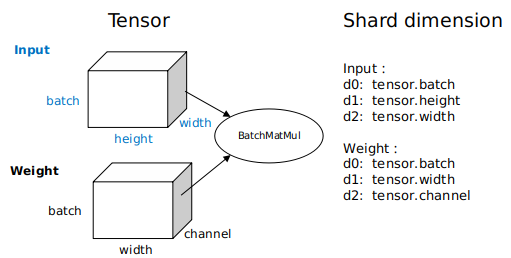
from mindspore.ops import operations as P
batch_matmul = P.BatchMatMul()
# 根据算子要输入的Tensor维度来配置切分策略
# 以MatMul算子为例,其一般有两个输入 input, weight, 假设其维度分别为[batch, height, width] [batch, width, channel]
# 因此可以分别为这两个Tensor配置切分策略
# 配置1:不做切分
batch_matmul.shard(((1, 1, 1), (1, 1, 1)),)
# 配置2:batch维度切分,切8份,8卡数据并行,只切数据,不切参数,batch要求能够被8整除,建议的数值有8,16,32,64....
batch_matmul.shard(((8, 1, 1), (1, 1, 1)),)
# 配置3:混合切分策略,数据和模型参数均切分, 数据切4份(dp),参数切2份(mp), 其中dp和mp值需遵循dp*mp <= total_device_num的原则
batch_matmul.shard(((4, 1, 1), (1, 1, 2)),)
张量排布变换(Tensor Redistribution)¶
当前一个算子的输出张量模型和后一个算子的输入张量模型不一致时,就需要引入计算、通信操作的方式实现张量排布间的变化。自动并行流程引入了张量重排布算法(Tensor Redistribution),可以推导得到任意排布的张量间通信转换方式。下面三个样例表示公式Z=(X×W)×V的并行计算过程,即两个二维矩阵乘操作,体现了不同并行方式间如何转换。
在样例一中,第一个数据并行矩阵乘的输出在行方向上存在切分,而第二个模型并行矩阵乘的输入需要全量张量,框架将会自动插入AllGather算子实现排布变换。
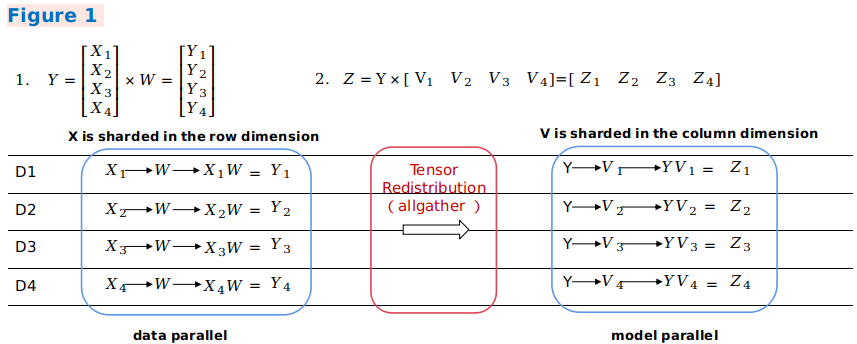
from mindspore.ops import operations as P
# 图1中的Y = X * W 计算
matmul_1 = P.MatMul()
# 在X的batch维度切分成4份,W不切分
matmul_1.shard(((4, 1, 1), (1, 1)),)
# X --> shape: [64, 196, 3] --> 切分成4份 X1: [16, 196, 3] X2: [16, 196, 3] X3: [16, 196, 3] X4: [16, 196, 3]
# W --> shape: [3, 32]
# 图1中的Z = Y * V 计算
matmul_2 = P.MatMul()
# Y不切分,V在channel维度切分成4份
matmul_2.shard(((1, 1, 1), (1, 4)),)
# Y --> shape: [64, 196, 32]
# V --> shape: [32, 768] --> channel维度切分成4份 V1: [64, 32, 192] V2: [32, 192] V3: [32, 192] V4: [32, 192]
Y = batch_matmul_1(X, W)
# 内部并行计算逻辑, X切分后使用Scatter算子进行Tensor分发到不同的设备上并行执行运算,具体分在哪台设备上运算由底层算法分配,上层不感知
# X1 * W --> Y1: shape [16, 196, 32] -- *device1
# X2 * W --> Y2: shape [16, 196, 32] -- *device2
# X3 * W --> Y3: shape [16, 196, 32] -- *device3
# X4 * W --> Y4: shape [16, 196, 32] -- *device4
# Y = [Y_c1, Y_c2, Y_c3, Y_c4]T 此时每个计算结果还保留在各自的设备上, T表示转置
# 由于matmul_2算子的输入Y 是 matmul_1算子的输出,但两者的切分策略不一致
# matmul_1.shard(((4, 1, 1), (1, 1)),) <--> matmul_2.shard(((1, 1, 1), (1, 4)),)
# 这就导致matmul_2要求的输入必须是一个完整的数据shape,因此在matmul_2计算前,要对matmul_1的输出做All-Gather,将分散在各个设备上的计算结果收集拼接并同步
Z = matmul_2(Y, V)
# 先经过All-Gather之后收集Y1, Y2, Y3, Y4 拼接成完整的数据Y: [64, 196, 32]
# 将V在channel维度切分成4份:
# V1: [32, 192]
# V2: [32, 192]
# V3: [32, 192]
# V4: [32, 192]
# 内部并行计算逻辑,V切分后使用Scatter算子分发Tensor给不同设备并行计算:
# Y * V1 --> Z1:shape [64, 196, 192] -- *device1
# Y * V2 --> Z2:shape [64, 196, 192] -- *device2
# Y * V3 --> Z3:shape [64, 196, 192] -- *device3
# Y * V4 --> Z4:shape [64, 196, 192] -- *device4
在样例二中,第一个模型并行矩阵乘的输出在列方向上存在切分,而第二个数据并行矩阵乘的输入在行方向上存在切分,框架将会自动插入等价于集合通信中AlltoAll操作的通信算子实现排布变换。
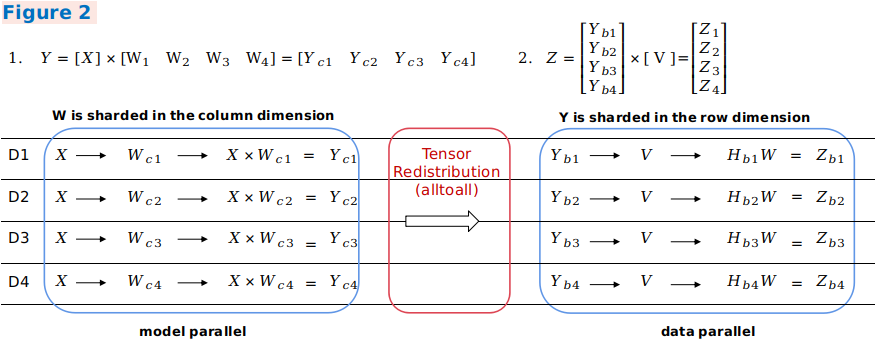
from mindspore.ops import operations as P
# 图2中的Y = X * W 计算
matmul_1 = P.MatMul()
# X不切分,W在channel维度切分成4份
matmul_1.shard(((1, 1, 1), (1, 4)),)
# X --> shape: [64, 196, 3]
# W --> shape: [3, 32] --> 在channel处切分: W_c1: [3, 8] W_c2: [3, 8] W_c3: [3, 8] W_c4: [3, 8]
# 图2中的Z = Y * V 计算
matmul_2 = P.MatMul()
# Y在batch维度切分,V不切分
matmul_2.shard(((4, 1, 1), (1, 1)),)
# Y --> shape: [64, 196, 32] --> batch维度切分成4份 V1: [16, 196, 32] V2: [16, 196, 32] V3: [16, 196, 32] V4: [16, 196, 32]
# V --> shape: [32, 768]
Y = matmul_1(X, W)
# 内部并行计算逻辑, 分别在不同的设备上并行执行运算,具体分在哪台设备上运算由底层分配,上层不感知
# X [64, 196, 3] * W_c1 [64, 3, 8] --> Y_c1: shape [64, 196, 8] -- *device1
# X * W_c2 --> Y_c2: shape [64, 196, 8] -- *device2
# X * W_c3 --> Y_c3: shape [64, 196, 8] -- *device3
# X * W_c4 --> Y_c4: shape [64, 196, 8] -- *device4
# Y = [Y_c1, Y_c2, Y_c3, Y_c4] 此时每个计算结果还保留在各自的设备上
# 由于matmul_2算子的输入Y 是 matmul_1算子的输出,但两者的切分策略不一致
# matmul_1.shard(((1, 1, 1), (1, 4)),) <--> matmul_2.shard(((4, 1, 1), (1, 1)),)
# 即需要将每个device上的 Tensor Shape [64, 196, 8] --> [16, 196, 32] Tensor Layout转换
# 这就导致matmul_2要求的输入不仅是完整的权重shape,而且需要进一步完成batch维度的切分操作。
# 通常的做法是先All-Gather,将Y转换成一个完整的权重shape: [64, 196, 32], 然后再执行Scatter操作,将Y在batch维度切分之后分发出去
# 然而All-To-All操作可以很方便且高效的同时完成上述两种操作,在All-Gather的同时进行Scatter,完成上述转换过程!
Z = matmul_2(Y, V)
# 先经过All-To-All之后完成Y在batch维度切分成4份并分发给不同的设备:
# Y_b1: [16, 196, 32]
# Y_b2: [16, 196, 32]
# Y_b3: [16, 196, 32]
# Y_b4: [16, 196, 32]
# 内部并行计算逻辑
# Y_b1 * V --> Z_b1:shape [ , 196, 192] -- *device1
# Y_b2 * V --> Z_b2:shape [64, 196, 192] -- *device2
# Y_b3 * V --> Z_b3:shape [64, 196, 192] -- *device3
# Y_b4 * V --> Z_b4:shape [64, 196, 192] -- *device4
在样例三中,第一个混合并行矩阵乘的输出切分方式和第二个混合并行矩阵乘的输入切分方式一致,所以不需要引入重排布变换。但由于第二个矩阵乘操作中,两个输入的相关维度存在切分,所以需要插入AllReduce算子保证运算正确性。
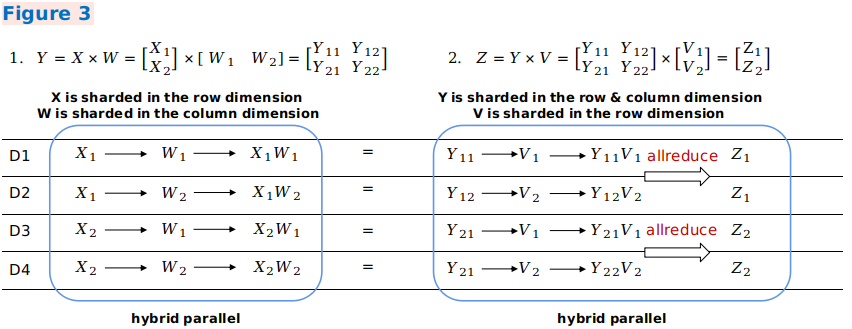
from mindspore.ops import operations as P
# 图3中的Y = X * W 计算
matmul_1 = P.MatMul()
# X在batch维度切2份,W在channel维度切分成2份
matmul_1.shard(((2, 1, 1), (1, 2)),)
# X --> shape: [64, 196, 3] --> 在batch处切分: X1:[32, 196, 3] X2: [32, 196, 3]
# W --> shape: [3, 32] --> 在channel处切分: W1: [3, 16] W2: [3, 16]
# 图3中的Z = Y * V 计算
matmul_2 = P.MatMul()
# Y在batch维度切分2份,V在batch维度切分2份
matmul_2.shard(((2, 1, 1), (2, 1)),)
# Y --> shape: [64, 196, 32] --> 在batch处切分: Y1:[32, 196, 32] Y2: [32, 196, 32]
# V --> shape: [32, 768] --> 在0维处切分: V1: [16, 768] V2: [16, 768]
Y = matmul_1(X, W)
# X, W 维度切分之后利用Scatter分发Tensor到不同设备上进行并行计算
# [X1, X2]T * [W1, W2] = [X1*W1, X1*W2 = [Y11, Y12
# X2*W1, X2*W2] Y21, Y22]
# X1([32, 196, 3]) * W1(3, 16) = Y11([32, 196, 16]) --> *device1
# X1([32, 196, 3]) * W2(3, 16) = Y12([32, 196, 16]) --> *device2
# X2([32, 196, 3]) * W1(3, 16) = Y21([32, 196, 16]) --> *device3
# X2([32, 196, 3]) * W1(3, 16) = Y22([32, 196, 16]) --> *device4
# 由于matmul_2算子的输入Y 是 matmul_1算子的输出,但两者的切分策略一致
# matmul_1.shard(((2, 1, 1), (1, 2)),) <--> matmul_2.shard(((2, 1, 1), (2, 1)),)
# 既不需要在中间插入额外Tensor Redistribution变换,直接可以使用各设备上的值进行运算
Z = matmul_2(Y, V)
# 由于对Tensor Y的切分策略相同,不需要再进行Tensor Redistribution,所以此处直接使用每台设备上相应的Y*切片即可
# V在切分之后,分发给不同的设备进行并行计算 [2,2] * [2,1] --> [2,1]
# [Y11, Y12 * [V1 = [Y11*V1 + Y12*V2 = [Z1
# Y21, Y22] V2] Y21*V1 + Y22*V2] Z2]
# Y11([32, 196, 16]) * V1([16, 768]) = Z11([32, 196, 768])
# Y12([32, 196, 16]) * V2([16, 768]) = Z12([32, 196, 768])
# Y21([32, 196, 16]) * V1([16, 768]) = Z21([32, 196, 768])
# Y22([32, 196, 16]) * V2([16, 768]) = Z22([32, 196, 768])
# Z11 + Z12 = Z1 All-Reduce(SUM)
# Z21 + Z22 = Z2 All-Reduce(SUM)
# 其中由于Y11*V1、Y12*V2、Y21*V1、Y22*V2分别在不同的设备上,因此要执行加法操作的话,必须要插入All-Reduce算子进行SUM的规约运算
综上,1、2两点是自动并行实现的基础,总体来说这种分布式表达打破了数据并行和模型并行的边界,轻松实现混合并行。
从脚本层面上,用户仅需构造单机网络,即可表达并行算法逻辑,框架将自动实现对整图切分。
切分策略搜索算法 当用户熟悉了算子的切分表达,并手动对算子配置切分策略,这就是
SEMI_AUTO_PARALLEL半自动并行模式。这种方式对手动调优有帮助,但还是具有一定的调试难度,用户需要掌握并行原理,并根据网络结构、集群拓扑等计算分析得到高性能的并行方案。为了帮助用户加速并行网络训练过程,在半自动并行模式的基础上,AUTO_PARALLEL自动并行模式支持并行策略传播(Sharding Propagation),能够有效地降低用户手配算子切分策略的工作量,算法将切分策略由用户配置的算子向未配置的算子传播。 为进一步降低用户手配算子切分策略的工作量,支持切分策略完全自动搜索。为此,围绕硬件平台构建相应的代价函数模型(Cost Model),计算出一定数据量、一定算子在不同切分策略下的计算开销(Computation Cost),内存开销(Memory Cost)及通信开销(Communication Cost)。然后通过动态规划算法(Dynamic Programming)或者递归规划算法(Recursive Programming),以单卡的内存上限为约束条件,高效地搜索出性能较优的切分策略。 策略搜索这一步骤代替了用户手动指定模型切分,在短时间内可以得到较高性能的切分方案,极大降低了并行训练的使用门槛。分布式自动微分 传统的手动模型切分除了需要关注正向网络通信还需要考虑网络反向的并行运算,MindSpore通过将通信操作包装为算子,并利用框架原有的自动微分操作自动生成通信算子反向,所以即便在进行分布式训练时,用户同样只需关注网络的前向传播,真正实现训练的全自动并行。
自动并行代码¶
张量排布模型
tensor_layout:这个目录下包含了张量排布模型相关功能的定义及实现。其中
tensor_layout.h中声明了一个张量排布模型需要具备的成员变量tensor_map_origin_,tensor_shape_和device_arrangement_等。在tensor_redistribution.h中声明了实现张量排布间from_origin_和to_origin_变换的相关方法,将推导得到的重排布操作保存在operator_list_中返回,并计算得到重排布所需的通信开销comm_cost_, 内存开销memory_cost_及计算开销computation_cost_。
分布式算子
ops_info:这个目录下包含了分布式算子的具体实现。在
operator_info.h中定义了分布式算子实现的基类OperatorInfo,开发一个分布式算子需要继承于这个基类并显式实现相关的虚函数。其中InferTensorInfo,InferTensorMap和InferDevMatrixShape函数定义了推导该算子输入、输出张量排布模型的算法。InferForwardCommunication,InferMirrorOps等函数定义了切分该算子需要插入的额外计算、通信操作。CheckStrategy和GenerateStrategies函数定义了算子切分策略校验和生成。根据切分策略SetCostUnderStrategy将会产生该策略下分布式算子的并行开销值operator_cost_。
策略搜索算法
auto_parallel:这个目录下实现了切分策略搜索的算法。
graph_costmodel.h定义了构图信息,其中每个点表示一个算子OperatorInfo,有向边edge_costmodel.h表示算子的输入输出关系及重排布的代价。operator_costmodel.h中定义了每个算子的代价模型,包括计算代价、通信代价和内存代价。dp_algorithm_costmodel.h主要描述了动态规划算法的主要流程,由一系列图操作组成。在costmodel.h中定义了cost和图操作的数据结构。
设备管理
device_manager.h:这个文件实现了集群设备通信组的创建及管理。其中设备矩阵模型由
device_matrix.h定义,通信域由group_manager.h管理。
整图切分
step_auto_parallel.h, step_parallel.h:这两个文件包含了自动并行流程的核心实现。首先由
step_auto_parallel.h调用策略搜索流程并产生分布式算子的OperatorInfo,然后在step_parallel.h中处理算子切分和张量重排布等流程,对单机计算图进行分布式改造。
通信算子反向
grad_comm_ops.py:这个文件定义了
AllReduce和AllGather等通信算子的反向操作。
自动并行案例¶
MindSpore2.0及之前版本在启动半自动和自动模式进行训练时,必须通过model.train(*args, **kwargs)接口进行训练,不支持自定义循环进行网络训练。
半自动并行¶
半自动并行模式相较于自动并行模式,需要用户手动配置每个算子的shard接口对并行策略进行调优。
以SemiAutoParallelNet为例,在半自动并行模式下的脚本代码如下,MatMul的切分策略为((1, 1),(1, 2)),指定self.weight在第二维度上被切分两份。
import numpy as np
import mindspore as ms
from mindspore.communication import init
from mindspore import ops, nn
class SemiAutoParallelNet(nn.Cell):
def __init__(self):
super(SemiAutoParallelNet, self).__init__()
# 初始化权重
weight_init = np.random.rand(128, 128).astype(np.float32)
self.weight = ms.Parameter(ms.Tensor(weight_init))
self.weight2 = ms.Parameter(ms.Tensor(weight_init))
# 设置切分策略。在construct中fc的输入有两个,第一个输入是x,第二个输入是权重self.weight
# 因此shard需要提供一个tuple元组,分别对应每个输入tensor在对应维度的切分份数
# (1,1)表示输入x的每一维度都没有切分
# (1,2)表示在self.weight的第二维度上切成了两份
# 切分的过程是在图编译的过程中,在编译完成后,self.weight的shape就会发生改变
self.fc = ops.MatMul().shard(((1, 1),(1, 2)))
self.reduce = ops.ReduceSum()
def construct(self, x):
# x shape [64, 196, 128] self.weight shape [128, 128]
# x 不切分, self.weight在第二个维度切分2份: [w1, w2]
# 内部并行计算逻辑:
# x([64, 196, 128]) * w1([128, 64]) = x1([64, 196, 64]) --> *device0
# x([64, 196, 128]) * w2([128, 64]) = x2([64, 196, 64]) --> *device1
# 结果:[x1, x2] 此时x1、x2还分布在各自device上
x = self.fc(x, self.weight)
# 在construct函数中去初始化并行调用operation算子时,相当于用户没有设置matmul算子的策略。
# 那么默认的策略会自动配置数据并行,即((8, 1), (1, 1))。其中8表示用户此次运行的卡数
# 显然当前算子的策略和上一个算子策略不匹配(上一个算子的输出是这个算子的输入时):shard(((1, 1),(1, 2))) <--> shard(((8, 1), (1, 1)))
# 因此需要引入Tensor Redistribution变换操作:
# 将: x1 [64, 196, 64] x2 [64, 196, 64] --> [8, 196, 128
# 8, 196, 128
# ..... ] # 8份
# 显然要完成这部分操作,要同时经过StrideSlice切片和All-Gather算子拼接同步结果,再经由Scatter算子分发重新切分的Tensor数据
# 此时每台设备(8 device)上x的shape均为 [8, 196, 128]
x = ops.MatMul()(x, self.weight2)
# 内部并行计算逻辑:
# x1([8, 196, 128]) * w([128, 128]) = x1([8, 196, 128]) --> *device0
# x2([8, 196, 128]) * w([128, 128]) = x2([8, 196, 128]) --> *device1
# .......8张卡同时运算 --> *device(2~7)
x = self.reduce(x, -1)
# 由于self.reduce没有配置并行策略,默认的策略为shard(((8, 1, 1),),),因此并行策略与上一个算子策略相同,故不需要插入额外的算子进行重排操作
# 直接可以并行计算得到每台设备的x值
return x
init()
ms.set_auto_parallel_context(parallel_mode=ms.ParallelMode.SEMI_AUTO_PARALLEL)
net = SemiAutoParallelNet()
model = ms.Model(net)
model.train(*args, **kwargs)
全自动并行¶
自动并行模式,融合了数据并行、模型并行及混合并行的分布式并行模式,可以自动建立代价模型,找到训练时间较短的并行策略,为用户选择合适的并行模式。MindSpore提供了如下的三种不同的策略搜索算法:
dynamic_programming:动态规划策略搜索算法。能够搜索出代价模型刻画的最优策略,但在搜索巨大网络模型的并行策略时耗时较长。其代价模型是围绕Ascend 910芯片基于内存的计算开销和通信开销对训练时间建模。recursive_programming:双递归策略搜索算法。对于巨大网络以及大规模多卡切分能够保证瞬间生成最优策略。其基于符号运算的代价模型可以自由适配不同的加速器集群。sharding_propagation:切分策略传播算法。由配置并行策略的算子向未配置的算子传播并行策略。在传播时,算法会尽量选取引发张量重排布通信最少的策略。关于算子的并行策略配置和张量重排布,可参考半自动并行。
用户可以通过如下代码去设置上述的策略搜索算法:
import mindspore as ms
# 设置动态规划算法进行策略搜索
ms.set_auto_parallel_context(parallel_mode=ms.ParallelMode.AUTO_PARALLEL, search_mode="dynamic_programming")
# 设置双递归方法进行策略搜索
ms.set_auto_parallel_context(parallel_mode=ms.ParallelMode.AUTO_PARALLEL, search_mode="recursive_programming")
# 设置切分策略传播算法
ms.set_auto_parallel_context(parallel_mode=ms.ParallelMode.AUTO_PARALLEL, search_mode="sharding_propagation")
在
sharding_propagation模式下,算法根据用户设置的shard策略传播到整个模型,在dynamic_programming模式下,用户设置的shard策略也会生效,不会被搜索出来的策略覆盖掉。在全自动并行模式下,如果需要对某个Cell里的所有算子手动配置数据并行策略,可用Cell.set_data_parallel()统一设置。
混合并行¶
在MindSpore中特指用户通过手动切分模型实现混合并行的场景,用户可以在网络结构中定义通信算子原语AllReduce和AllGather等,手动执行并行流程。此时,用户需要自己实现参数的切分,算子切分后的通信等操作。例如下面的代码示例:
import numpy as np
import mindspore as ms
from mindspore.communication import init
from mindspore import ops, nn
class HybridParallelNet(nn.Cell):
def __init__(self):
super(HybridParallelNet, self).__init__()
# 以下2卡运行的场景为例子,实现分布式矩阵乘法来模拟单卡矩阵乘的结果。
# 即原始的逻辑
# 输入x,weight的shape分别为(32, 512), (512, 128)
# 经过计算:matmul(x, weight)
# 输出结果shape为(32, 128)的tensor
# 下面我们手动实现上面的矩阵乘法逻辑
# 我们需要手动的指定当前权重的切片的shape,我们希望在matmul的相关维度进行切分。相关维度切分的情况下
# 需要对matmul的结果进行AllReduce操作,确保数值和单机的保持一致
#
# 分布式逻辑
# 输入x,weight的shape分别为(32, 256), (256, 128)
# 经过计算 output = matmul(x, weight)
# output = allreduce(output)
# 输出结果shape为(32, 128)的tensor
weight_init = np.random.rand(256, 128).astype(np.float32)
self.weight = ms.Parameter(ms.Tensor(weight_init))
self.fc = ops.MatMul()
self.reduce = ops.AllReduce()
def construct(self, x):
x = self.fc(x, self.weight)
x = self.reduce(x)
return x
init()
ms.set_auto_parallel_context(parallel_mode=ms.ParallelMode.HYBRID_PARALLEL)
net = HybridParallelNet()
model = ms.Model(net)
model.train(*args, **kwargs)
数据导入方式¶
在并行训练中,支持三种数据的导入方式:
全量导入。仅在半自动和全自动并行模式下生效。用户可以通过
set_auto_parallel_context(full_batch=True)开启。开启全量导入之后,在自动并行流程中认为读入的batch是一个网络输入的完整shape。例如,在8卡训练的情况下,假设每张卡dataset返回的shape是[32, 8],那么当前一个迭代训练的训练的数据即为[32, 8]。因此,用户需要保证每卡在每轮迭代输入的数据是一致的。例如,确保每卡数据集的shuffle的顺序是一致的。数据并行导入。用户不设置
full_batch的情况下,每卡读入的数据是当前训练迭代的一个分片,因此要求每卡读入的数据内容不一样。例如8卡训练的情况下,每卡读入数据的shape为[32,8],那么当前一个迭代训练的数据总量为[32*8, 8]。模型并行导入。模型并行导入的方式主要针对图像领域中图像尺寸太大无法在单卡进行计算时,直接在输入流程上就对图像进行切分。MindSpore在
set_auto_parallel_context中提供了dataset_strategy接口,用户可以通过这个接口配置更加灵活的输入策略。注意,当用户使用此接口时,需要确保dataset返回的tensor符合对应的切分策略。如下代码所示:
import mindspore as ms
# 设置输入在第1维度上进行切分, 此时要求用户确保dataset返回的输入在第1维度上进行切分
ms.set_auto_parallel_context(dataset_strategy=((1, 8), (1, 8)))
# 相当于设置full_batch=False
ms.set_auto_parallel_context(dataset_strategy="data_parallel")
# 相当于设置full_batch=True
ms.set_auto_parallel_context(dataset_strategy="full_batch")
因此,在用户设置上述的配置之后,需要手动设置dataset的获取顺序,确保每卡的数据是期望的。
流水线并行¶
MindFormers 并行手册¶
MindFormers 并行设计¶
MindFormers集成了MindSpore原生的并行能力,在transformer API中利用配置化方式对Transformer网络做并行配置。

MindFormers支持基于Transformer API开发的大模型通过配置化接口进行并行配置,主要提供两种使用方式:1. config配置文件; 2. Trainer高阶接口;
config 并行配置¶
配置文件介绍及使用请参见:MindFormers Config 配置,主要用于run_mindformer.py脚本启动时使用。
用户可通过提供的并行模块和关键字,完成并行策略的设定:
use_parallel: 是否开启并行
parallel: 自动并行配置,相关入参支持可参考:mindspore.set_auto_parallel_context
parallel_mode: 并行模式,0-dataset数据并行, 1-semi半自动并行, 2-auto自动并行, 3-hybrid手工实现并行
gradients_mean: 是否在梯度AllReduce后执行平均算子。通常半自动并行模式下为False,数据并行模式下为True
enable_alltoall: 允许在通信期间生成AllToAll通信算子的开关。通常仅在MOE场景下打开,默认False
full_batch: 在auto_parallel模式下加载整个batch数据集时为True。半自动并行模式通常设置为True,数据并行模式必须设置为False,否则会报错
search_mode: 策略搜索模式,有三种,分别是recursive_programming,dynamic_programming和sharding_propagation。仅在全自动并行模式下生效,其他模式不生效,实验性接口,谨慎使用
enable_parallel_optimizer: 数据并行训练时对权重更新计算进行分片。优化器并行开关,在数据并行训练时默认会将模型权重参数切分成device_num份,与parallel_config中optimizer_shard保持一致;半自动并行时默认将模型权重参数切份data_parallel份
strategy_ckpt_save_file: 保存并行切分策略的路径。
parallel_config: 并行策略配置,相关入参配置可参考transformer.TransformerOpParallelConfig
data_parallel: 数据并行
model_parallel: 模型并行
pipeline_stage: 流水线并行
optimizer_shard: 是否开启优化器切分。优化器并行开关,通常在半自动并行模式下生效,与parallel中的enable_parallel_optimizer保持一致,默认将模型权重参数切份data_parallel份
micro_batch_num: 流水线并行的微批次大小。pipeline_satge大于1时,开启流水并行时使用,此处需满足micro_batch_num >= pipeline_satge
gradient_aggregation_group: 梯度通信算子融合组的大小
Trainer 并行配置¶
MindFormers Trainer接口介绍请见:MindFormers Trainer API
利用 Trainer.set_parallel_config(**kwargs)来为模型设定切分策略:set_parallel_config
使用样例:
import argparse
from mindformers import Trainer, TrainingArguments
from mindformers import init_context, ContextConfig, ParallelContextConfig
############################################# 并行环境初始化 ##################################################
def context_init(use_parallel=False, optimizer_parallel=False):
"""init context for mindspore."""
context_config = ContextConfig(mode=0, device_target="Ascend", device_id=0)
parallel_config = None
if use_parallel:
parallel_config = ParallelContextConfig(parallel_mode='SEMI_AUTO_PARALLEL',
gradients_mean=False,
enable_parallel_optimizer=optimizer_parallel,
full_batch=True)
rank_id, device_num = init_context(use_parallel=use_parallel,
context_config=context_config,
parallel_config=parallel_config)
############################################# 并行环境初始化 ##################################################
def main(use_parallel=False,
run_mode='train',
task='text_generation',
model_type='gpt2',
pet_method='',
train_dataset='./train',
eval_dataset='./eval',
predict_data='hello!',
dp=1, mp=1, pp=1, micro_size=1, op=False):
# 环境初始化
context_init(use_parallel, op)
# 训练超参数定义
training_args = TrainingArguments(num_train_epochs=1, batch_size=2, learning_rate=0.001, warmup_steps=100,
sink_mode=True, sink_size=2)
# 定义任务,预先准备好相应数据集
task = Trainer(task=task,
model=model_type,
pet_method=pet_method,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset)
############################################# 设定并行策略 ##################################################
task.set_parallel_config(data_parallel=dp,
model_parallel=mp,
pipeline_stage=pp,
optimizer_shard=op,
micro_batch_num=micro_size)
############################################# 设定并行策略 ##################################################
if run_mode == 'train':
task.train()
elif run_mode == 'finetune':
task.finetune()
elif run_mode == 'eval':
task.evaluate()
elif run_mode == 'predict':
result = task.predict(input_data=predict_data)
print(result)
并行注意事项¶
-data_parallel * model_parallel * pipeline_stage <= total_device_num;
-micro_batch_num >= pipeline_satge,micro_batch_num的大小通常越高,流水并行的效率就越好,但是往往会导致编译时间过长和Task Stream超限2016的问题,请根据实际情况调整该数值;
-model_parallel的大小通常和Transformer中hidden_size或vocab_size的大小相关,需要满足model_parallel % hidden_size == 0,不然会导致相应参数无法切分,从而引入额外的算子重排,引起性能劣化;
-pipeline_satge的大小通常和Transformer中num_layers的大小相关,建议配比满足num_layers % pipeline_satge == 0,使得Transformer的Layer层可以被均匀切分到不同的卡上,如果无法被均匀切分,容易导致编译时间过长或者编译失败
LLM 模型相关配置说明:
model: 模型配置
arch: 模型类配置
type: 模型类
model_config: 模型参数配置
type: 模型参数配置类
checkpoint_name_or_path: 评估时不指定权重,模型默认加载的权重名
# 以下配置针对大规模语言模型推理
top_k: 从概率最大的top_k个tokens中采样
top_p: 从概率最大且概率累计不超过top_p的tokens中采样
do_sample: 使能top_k或top_p采样,为False时top_k和top_p均重置为1
use_past: 使能增量推理,为True时为增量推理,否则为自回归推理,使用时请参考模型支持列表
max_decode_length: 文本生成最大长度(输入长度统计在内)
repetition_penalty: 重复文本惩罚系数,该值不小于1,等于1时不惩罚