Pipeline 组件¶
Task Pipeline 设计
MindFormers大模型套件面向任务设计pipeline推理接口,旨在让用户可以便捷的体验不同AI领域的大模型在线推理服务。
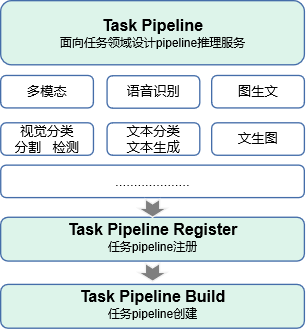
Task Pipeline
MindFormers大模型套件为用户提供了pipeline高阶API,支持用户便捷的使用套件中已经集成的任务和模型完成推理流程。
MindFormers 任务推理支持情况一览表:
| 任务 | 支持模型 | 支持推理数据 |
|---|---|---|
| text_generation | gpt2 gpt2_13b gpt2_52b pangualpha_2_6_b pangualpha_13b glm_6b glm_6b_lora llama_7b llama_13b llama_65b llama_7b_lora bloom_560m bloom_7.1b bloom_65b bloom_176b |
文本数据 |
| text_classification | txtcls_bert_base_uncased txtcls_bert_base_uncased_mnli |
文本数据 |
| token_classification | tokcls_bert_base_chinese tokcls_bert_base_chinese_cluener |
文本数据 |
| question_answering | qa_bert_base_uncased qa_bert_base_chinese_uncased |
文本数据 |
| translation | t5_small | 文本数据 |
| masked_image_modeling | mae_vit_base_p16 | |
| image_classification | vit_base_p16 swin_base_p4w7 |
图像数据 |
| zero_shot_image_classification | clip_vit_b_32 clip_vit_b_16 clip_vit_l_14 clip_vit_l_14@336 |
图像和文本对数据 |
文本生成¶
任务简介:
文本生成:生成自然语言文本。模型根据输入的文本和上下文生成类似人类语言的新文本。该任务可以应用于各种应用程序,如聊天机器人、自动摘要、机器翻译、文章生成等。
支持模型:
使用样例:
from mindformers.pipeline import pipeline
pipeline_task = pipeline("text_generation", model='gpt2', max_length=20)
pipeline_result = pipeline_task("I love Beijing, because", top_k=3)
print(pipeline_result)
文本分类¶
任务简介:
文本分类:模型在基于文本对的微调后,可以在给定任意文本对与候选标签列表的情况下,完成对文本对关系的分类,文本对的两个文本之间以-分割。
支持模型:
使用样例:
from mindformers.pipeline import TextClassificationPipeline
from mindformers import AutoTokenizer, BertForMultipleChoice, AutoConfig
input_data = ["The new rights are nice enough-Everyone really likes the newest benefits ",
"i don't know um do you do a lot of camping-I know exactly."]
tokenizer = AutoTokenizer.from_pretrained('txtcls_bert_base_uncased_mnli')
txtcls_mnli_config = AutoConfig.from_pretrained('txtcls_bert_base_uncased_mnli')
# Because batch_size parameter is required when bert model is created, and pipeline
# function deals with samples one by one, the batch_size parameter is seted one.
txtcls_mnli_config.batch_size = 1
model = BertForMultipleChoice(txtcls_mnli_config)
txtcls_pipeline = TextClassificationPipeline(task='text_classification',
model=model,
tokenizer=tokenizer,
max_length=model.config.seq_length,
padding="max_length")
results = txtcls_pipeline(input_data, top_k=1)
print(results)
# 输出
# [[{'label': 'neutral', 'score': 0.9714198708534241}], [{'label': 'contradiction', 'score': 0.9967639446258545}]]
命名实体识别¶
任务简介:
命名实体识别:模型在基于命名实体识别数据集的微调后,可以在给定任意文本与候选标签列表的情况下,完成对文本中命名实体的识别。
支持模型:
使用样例:
from mindformers.pipeline import TokenClassificationPipeline
from mindformers import AutoTokenizer, BertForTokenClassification, AutoConfig
from mindformers.dataset.labels import cluener_labels
input_data = ["表身刻有代表日内瓦钟表匠freresoltramare的“fo”字样。"]
id2label = {label_id: label for label_id, label in enumerate(cluener_labels)}
tokenizer = AutoTokenizer.from_pretrained('tokcls_bert_base_chinese_cluener')
tokcls_cluener_config = AutoConfig.from_pretrained('tokcls_bert_base_chinese_cluener')
# This is a known issue, you need to specify batch size equal to 1 when creating bert model.
tokcls_cluener_config.batch_size = 1
model = BertForTokenClassification(tokcls_cluener_config)
tokcls_pipeline = TokenClassificationPipeline(task='token_classification',
model=model,
id2label=id2label,
tokenizer=tokenizer,
max_length=model.config.seq_length,
padding="max_length")
results = tokcls_pipeline(input_data)
print(results)
# 输出
# [[{'entity_group': 'address', 'start': 6, 'end': 8, 'score': 0.52329, 'word': '日内瓦'},
# {'entity_group': 'name', 'start': 12, 'end': 25, 'score': 0.83922, 'word': 'freresoltramar'}]]
问答任务¶
任务简介:
问答任务:模型在基于问答数据集的微调后,输入为上下文(context)和问题(question),模型根据上下文(context)给出相应的回答。
支持模型:
使用样例:
from mindformers.pipeline import QuestionAnsweringPipeline
from mindformers import AutoTokenizer, BertForQuestionAnswering, AutoConfig
# 测试数据,测试数据分为context和question两部分,两者以 “-” 分隔
input_data = ["My name is Wolfgang and I live in Berlin - Where do I live?"]
tokenizer = AutoTokenizer.from_pretrained('qa_bert_base_uncased_squad')
qa_squad_config = AutoConfig.from_pretrained('qa_bert_base_uncased_squad')
# This is a known issue, you need to specify batch size equal to 1 when creating bert model.
qa_squad_config.batch_size = 1
model = BertForQuestionAnswering(qa_squad_config)
qa_pipeline = QuestionAnsweringPipeline(task='question_answering',
model=model,
tokenizer=tokenizer)
results = qa_pipeline(input_data)
print(results)
# 输出
# [{'text': 'Berlin', 'score': 0.9941, 'start': 34, 'end': 40}]
翻译¶
任务简介:
翻译:将一种语言翻译成另一种语言,即进行机器翻译。模型在输入一段文本后,输出对应的翻译结果。例如,将英语句子翻译成法语、汉语、德语等其他语言。
支持模型:
使用样例:
from mindformers.pipeline import pipeline
pipeline_task = pipeline("translation", model='t5_small')
pipeline_result = pipeline_task("translate the English to Romanian: a good boy!", top_k=3)
print(pipeline_result)
#[{'translation_text': ['un băiat bun!']}]
图像掩码建模¶
任务简介:
图像掩码建模:通过遮蔽图像中的某些部分来预测被遮蔽的部分。这个任务通常涉及在图像中指定一个区域,并将该区域遮蔽,然后使用遮蔽的图像作为输入,从未遮蔽的图像区域中预测遮蔽的部分。这种任务在计算机视觉中被广泛应用,例如,在图像修复和图像合成中,可以使用遮蔽建模来修复或合成图像中的缺失或不完整部分。
支持模型:
使用样例:
from mindformers.pipeline import pipeline
from mindformers.tools.image_tools import load_image
pipeline_task = pipeline("masked_image_modeling", model='mae_vit_base_p16')
img = load_image("https://ascend-repo-modelzoo.obs.cn-east-2.myhuaweicloud.com/XFormer_for_mindspore/clip/sunflower.png")
pipeline_result = pipeline_task(img)
图像分类¶
任务简介:
图像分类:将输入的图像识别为属于哪一类别。例如,输入一张狗的图片,模型可以识别出这是一只狗,并将其分类为狗这一类别。这种图像分类任务可用于许多应用,如智能相册、图像搜索、人脸识别、安防监控等。
支持模型:
使用样例:
from mindformers.pipeline import pipeline
from mindformers.tools.image_tools import load_image
pipeline_task = pipeline("image_classification", model='vit_base_p16')
img = load_image("https://ascend-repo-modelzoo.obs.cn-east-2.myhuaweicloud.com/XFormer_for_mindspore/clip/sunflower.png")
pipeline_result = pipeline_task(img, top_k=3)
使用样例:
from mindformers.pipeline import pipeline
from mindformers.tools.image_tools import load_image
pipeline_task = pipeline("image_classification", model='swin_base_p4w7')
img = load_image("https://ascend-repo-modelzoo.obs.cn-east-2."
"myhuaweicloud.com/XFormer_for_mindspore/clip/sunflower.png")
pipeline_result = pipeline_task(img, top_k=3)
print(pipeline_result)
# 输出
# [[{'score': 0.89573187, 'label': 'daisy'}, {'score': 0.005366202, 'label': 'bee'},
# {'score': 0.0013296203, 'label': 'fly'}]]
零样本图像分类¶
任务简介:
零样本图像分类:模型在基于图文对的预训练后,可以在给定任意图片与候选标签列表的情况下,完成对图像的分类,而无需任何微调。
支持模型:
使用样例:
from mindformers import pipeline
from mindformers.tools.image_tools import load_image
classifier = pipeline("zero_shot_image_classification",
model='clip_vit_b_32',
candidate_labels=["sunflower", "tree", "dog", "cat", "toy"])
img = load_image("https://ascend-repo-modelzoo.obs.cn-east-2."
"myhuaweicloud.com/XFormer_for_mindspore/clip/sunflower.png")
classifier(img)
# result
# [[{'score': 0.99995565, 'label': 'sunflower'},
# {'score': 2.5318595e-05, 'label': 'toy'},
# {'score': 9.903885e-06, 'label': 'dog'},
# {'score': 6.75336e-06, 'label': 'tree'},
# {'score': 2.396818e-06, 'label': 'cat'}]]